Table of Contents
- Decision
The utilization and adoption of Machine learning get developed signally in the last decade or so. In fact, this age can be titled as one of the most revolutionary and significant periods in terms of technology. The impact of machine learning is so much that it has begun to guide our lives prevalently.
We are living in a human beings wherein every last things that were one time called manual tasks are getting transformed into automated ones and the reason why this is happening is because of political machine learning. It stands as the reasonableness behind the creation of many interactional software system applications, robots acting surgeries, computers playing chess, the conversion of large frame computers into PCs, self-determined cars, interactive online learnedness solutions, amongst many else things.
Technology is consistently evolving at an horrifying rate. If we analyze the computing advances made over the recent years, one affair that is easy predictable is the bright future that lies ahead of us.
That being same, the reason wherefore data scientists have been competent to address the ever-so complex nature of first-hand problems with field of study solutions is by the utilization of special machine learning algorithms that have been developed to solve these problems perfectly well. And to say the least, the outcomes have been extraordinary until today.
In that blog, we will inclination devour 10 machine learning algorithms that data scientists must know approximately. In sheath you are a information man of science, an aspiring one, or if you're merely intrigued by machine learning, then knowing about these algorithms will be extremely helpful.
However, before we startle onto learning about the 10 simple machine learning algorithms, let's first off understand two main types of machine learning techniques. These techniques are the grounding for understanding the ten machine learning algorithms.
There are two principal types of machine learning techniques:
What is Supervised Learning?
The supervised political machine learning follows a exemplary that forms predictions depending on the evidence of uncertainty. To put this in easy footing, a supervised learning algorithm is reliant on a previously noted set of inputs and their relevant outputs. It plays a role in making deductive predictions with the responses to fresh data.
Data scientists can use supervised learning in case they give already known data for the output that they wish to predict. What is more, supervised encyclopaedism is carried with the usage of classification and regression methods for the enhancement of prognosticative models.
Classification Technique: This technique is used for predicting rather distinct responses. For instance; if you deficiency to get hold out if an e-mail is authentic or spam, a tumour is cancerous or showtime then you can use the compartmentalization technique.
The most mutual applications of this technique include speech acknowledgment, medical imaging, quotation scoring, etc. The common machine learning algorithms that are exploited for playacting compartmentalisation let in the k-nighest, discriminant analysis, boosted, bagged conclusion Tree, support vector motorcar (SVM), neural networks, etc.
Regression Technique: In order to call the continuous responses so much as a change in temperature, fluctuations in the power demand then regression technique is used. The most popular applications of this proficiency include electricity shipment, algorithmic trading, forecasting, etc.
Data scientists use regression techniques if they are working with a data run or in case the nature of a particular response comes kayoed to be a real like temperature or time. The machine learning algorithms include linear model, regulation, stepwise regression, bagged decision trees, not-bilinear model, etc.
What is Unsupervised Learning?
Unsupervised learning is used when the objective is to find the hidden patterns or any intrinsic structures within the information. It enables the information scientists to draw important inferences from datasets that consist of input data without whatever labelled responses.
Clustering: The to the highest degree common unsupervised learning technique is referred to as clustering. This technique is utilised for the role of exploratory information depth psychology to discover obscure patterns or groupings in the data. The most frequent applications of bunch include grocery store research, gene sequence analysis, object recognition, etc.
The commonly used algorithms for performing clustering include k-way and k-medoids, Mathematician mixture models, hierarchical cluster, hidden Markov models, ablative clustering, etc
Visualisation Algorithm: The unsupervised algorithms that affirm the information which is non labelled while showcasing IT in the form of an intuitive structure, for the most part in 2D surgery 3D is titled a Visualization algorithmic program. This data set on the nose differs in understandable clusters to increase understanding.
Unusual person Detection: The algorithmic rule detection is used to catch out the likely anomalies within the data. It tin exist used for detection any suspicious credit minutes, differentiating criminals from a set of people, etc.
Rule Data Scientist Follow While Choosing Between Supervised and Unsupervised Machine Learning
- The supervised learning proficiency is chosen when the data scientists want to develop a pose for making predictions. For instance: predicting the future of a continuous unsettled such American Samoa temperature or a stock price. To boot, they are also old while doing a classification. For model: finding if an e-mail is from an authentic source or if it is spam.
- Data scientists choose unsupervised learning if there is a need to explore a set of data or training a modelling for determination a good representation like the outgrowth of cacophonic the information into clusters.
Now that we sustain laid a foundation of the machine learnedness techniques, let's jump right into the top 10 political machine learning algorithms that all data scientists must know about.
1. Linear Fixation
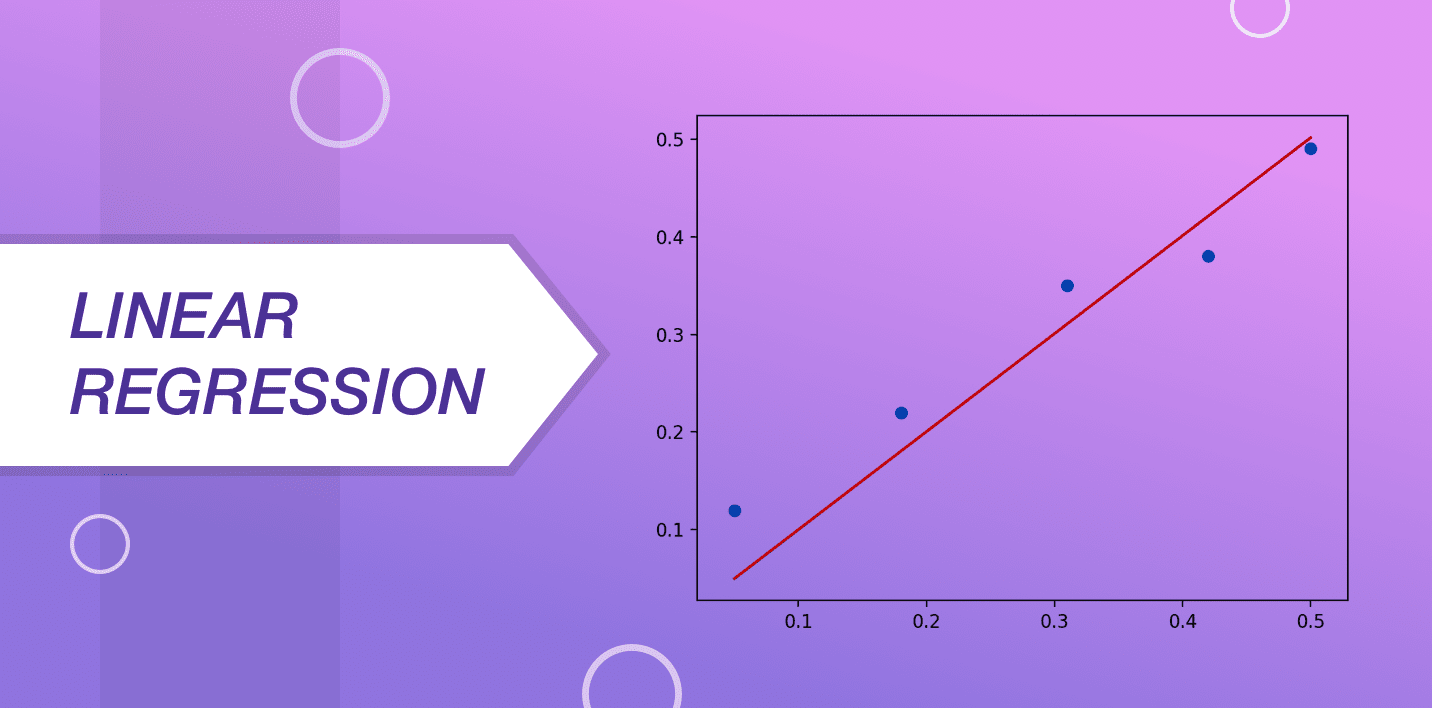
Additive regression is known as a extremely used and prevalent machine learning algorithm that is utilized by data scientists across the world. In order to understand the functionality of this algorithm, imagine a localise of stones that are in the placement of ascending weights.
The restriction here is that you cannot matter these stones away yourself. You leave have to guess the weight of these logs past looking at at their height and shape spell arranging them with a categorization that is supported visual parameters. This is precisely what linear fixation is all about.
The representation of rectilinear regression is done with an equation defining a line that fits very well into the family relationship between the input variables and the outturn variable. This line is referred to as the regression line and it is primarily shown with an equation:
Y = a*X + b
In this equation, "y" is a dependent variable, "a" is the slope, "X" is an independent variable and "b" is the bug. The end of one-dimensional regression is to find the values of coefficients "a" and "b".
2. Logistic Regression
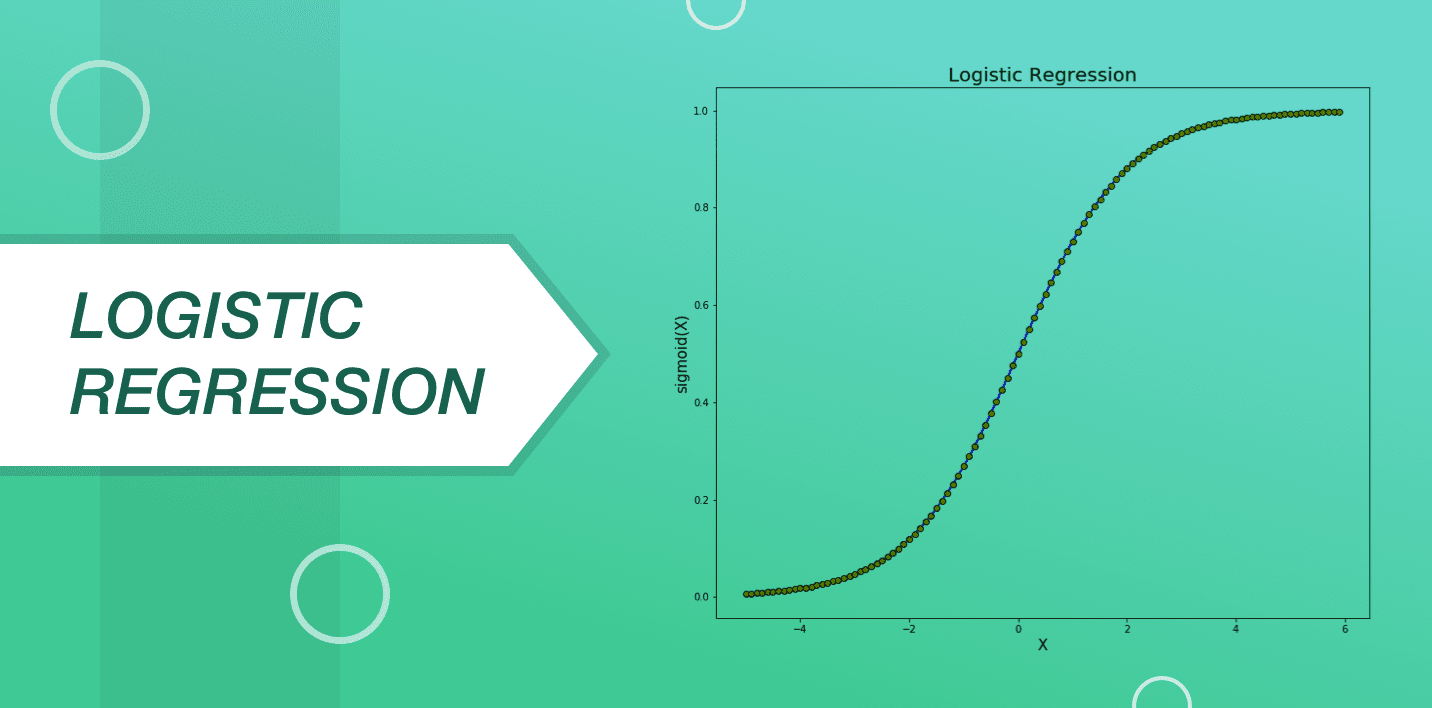
This algorithm is derived from the field of statistics. IT is considered to glucinium a dependable method for performance binary sorting problems. The primary aim of logistic regression is to observe the values for the coefficients representing all the input signal variables. Strange than linear infantile fixation, the common output predicted for logistic arrested development is changed using a nonlinear function known Eastern Samoa a logistic function.
The logistic occasion is in the anatomy of a big "S" and is used to modify any value ranging from 0 to 1. It is helpful in applying a specific rule to the output of the logistic function for changing values from 0 to 1. Callable to the way in which this model is grasped or identifies, the important predictions implemented by the logistic regression can be utilised as the probability of any data that belongs to classes 0 or 1. This can beryllium victimised to solve problems where more thought inevitably to be apt to a forecasting.
Workings in a sense very similar to bilinear regression, the logic regression is complete the more effective at the time when the attributes that are not linked to the turnout variable along with the attributes that are the same in nature get far.
3. Decision Tree
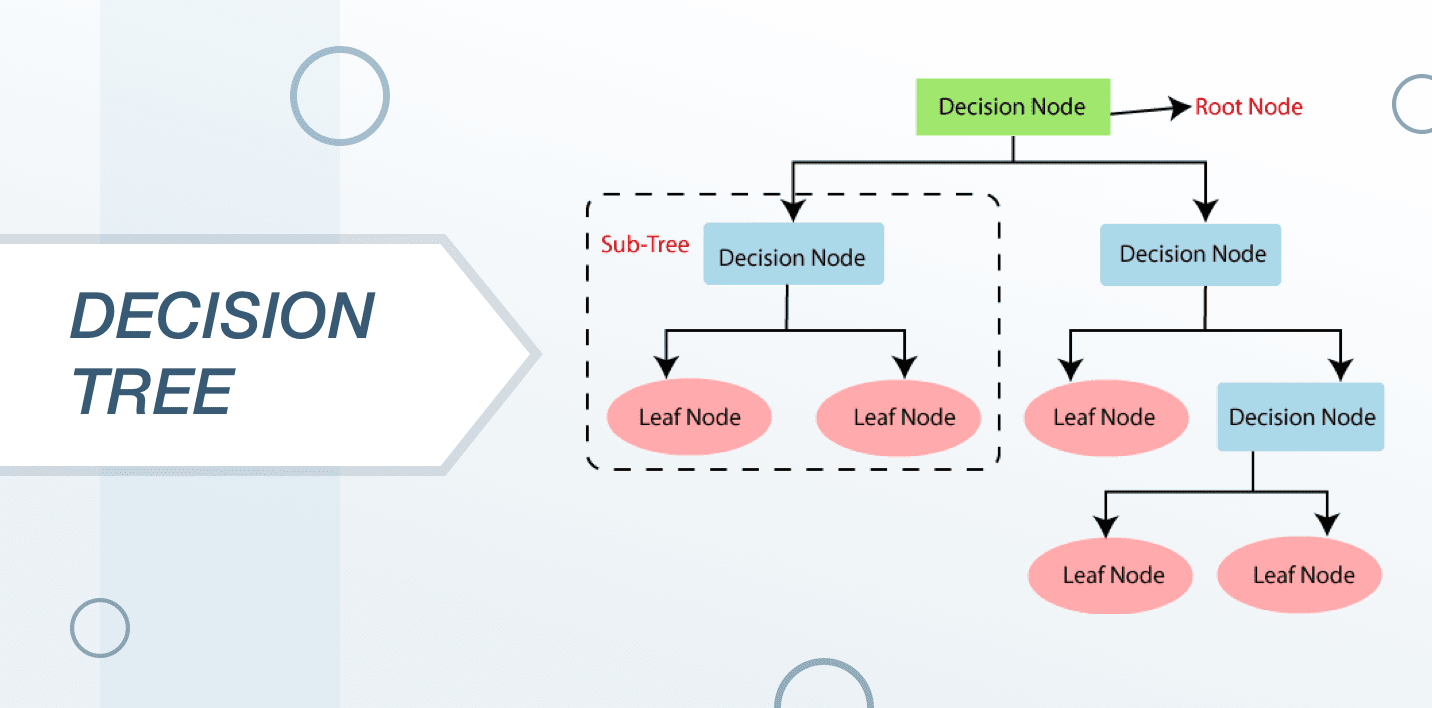 The decision tree is one of the almost commonly exploited automobile learnedness algorithms. It is in essence a supervised learning algorithm that works very well for classifying problems. IT is utilized for classifying some the variables that are both free burning and specific.
The decision tree is one of the almost commonly exploited automobile learnedness algorithms. It is in essence a supervised learning algorithm that works very well for classifying problems. IT is utilized for classifying some the variables that are both free burning and specific.
Unremarkably used in statistics and information analytics for the function of predictive models, the structure of this algorithmic program is represented with the help of leaves and branches. The attributes of the objective function are supported the branches of the decision tree, the values of the objective function are recorded in the leaves and the remaining nodes contain attributes for which the cases differ.
Systematic to classify a new example, the data scientists are supposed to go down the lead in order to give the appropriate respect. The objective is to create a model that can prognosticate the treasure of the target variable which is qualified on many input variables.
4. Financial backing Vector Machines
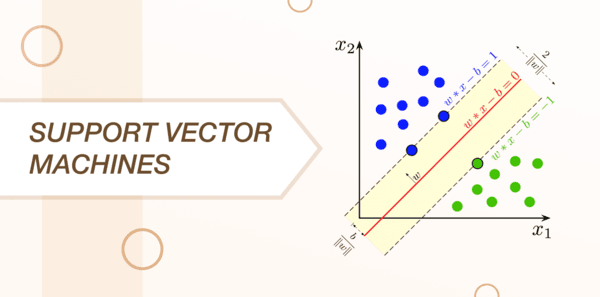 A linelike model which works rattling more than happening the lines of both additive and supplying regression is called as the indorse vector machine. Information technology is more ilk a method of compartmentalisation in which the data scientists plot raw data with points in the n-dimensional space; where n is known as the phone number of features.
A linelike model which works rattling more than happening the lines of both additive and supplying regression is called as the indorse vector machine. Information technology is more ilk a method of compartmentalisation in which the data scientists plot raw data with points in the n-dimensional space; where n is known as the phone number of features.
Every feature has a value which then gets tied leading to a fussy coordinate that makes the process of classifying data selfsame simple. The data is and then fall apart and plotted in a detailed style connected a graph with lines titled classifiers.
The SVM algorithm is usually used to define an optimal hyperplane with an optimized allowance, map data to a high dimensional space so that it becomes easier to classify with linear decision surfaces and redevelop problems so that the data is mapped implicitly into place.
5. Naive Bayes
 Naive Bayes is popularly known as an easy to use but an impactful motorcar encyclopaedism algorithm that is utilized for the purpose of predictive modelling. It is myrmecophilous on a model that majorly includes two types of probabilities that are calculated aligned up by the inputs of breeding data.
Naive Bayes is popularly known as an easy to use but an impactful motorcar encyclopaedism algorithm that is utilized for the purpose of predictive modelling. It is myrmecophilous on a model that majorly includes two types of probabilities that are calculated aligned up by the inputs of breeding data.
The probability of every class is considered as the first and the conditional probability for every class presented x valuate is considered second. Upon the completion of the calculation, the probability model is used for making predictions on new information with the assistanc of the Bayes Theorem. In example the data is supported real values, information technology is much common to consider it as a Gaussian distribution so that the probabilities can follow quickly derived.
Wide-eyed Bayes has the word naive due to the fact that it assumes each input variable to represent independent which can be a fertile and fantastic assumption for the real data. Regardless, this technique is extremely impactful when it comes to a panoramic stray of difficult problems.
6. k-NN (k-Nearest Neighbours)
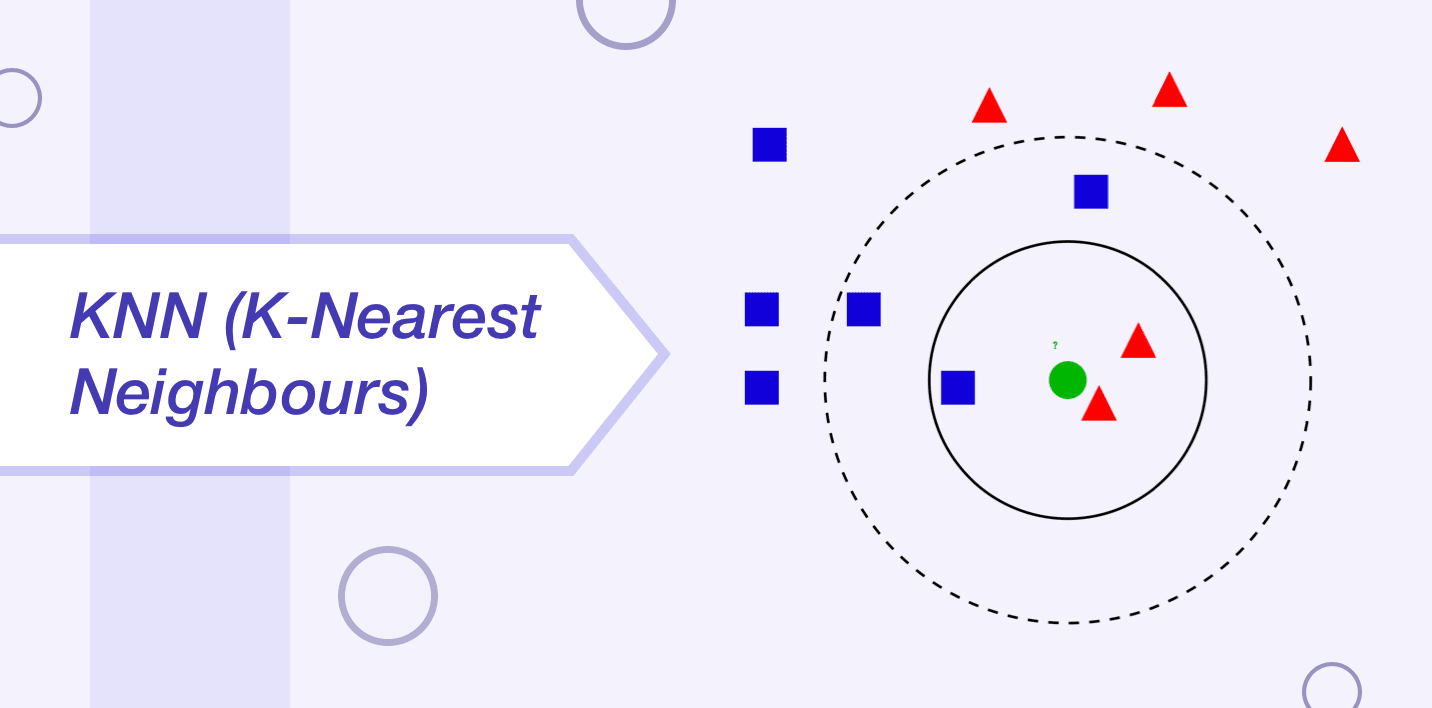 The k-NN algorithm can buoy live used for the classification as well as the regression problems. IT is used very commonly by the data scientists for solving the data classification problems. IT is a pretty easy algorithm that is used for storing the available cases while also labelling any revealed cases or taking a under consideration vote of k-neighbours.
The k-NN algorithm can buoy live used for the classification as well as the regression problems. IT is used very commonly by the data scientists for solving the data classification problems. IT is a pretty easy algorithm that is used for storing the available cases while also labelling any revealed cases or taking a under consideration vote of k-neighbours.
Afterwards that, the case is assigned to the class with which it matches ordinarily. A distance work is normally used for playing this measurement. KNN requires a major part of the store for the purpose of storing the data, but it simply carries down a calculation at the time when a prediction is required. Information technology is possible to update breeding part with metre just for the sake of maintaining precise predictions.
7. K-Means
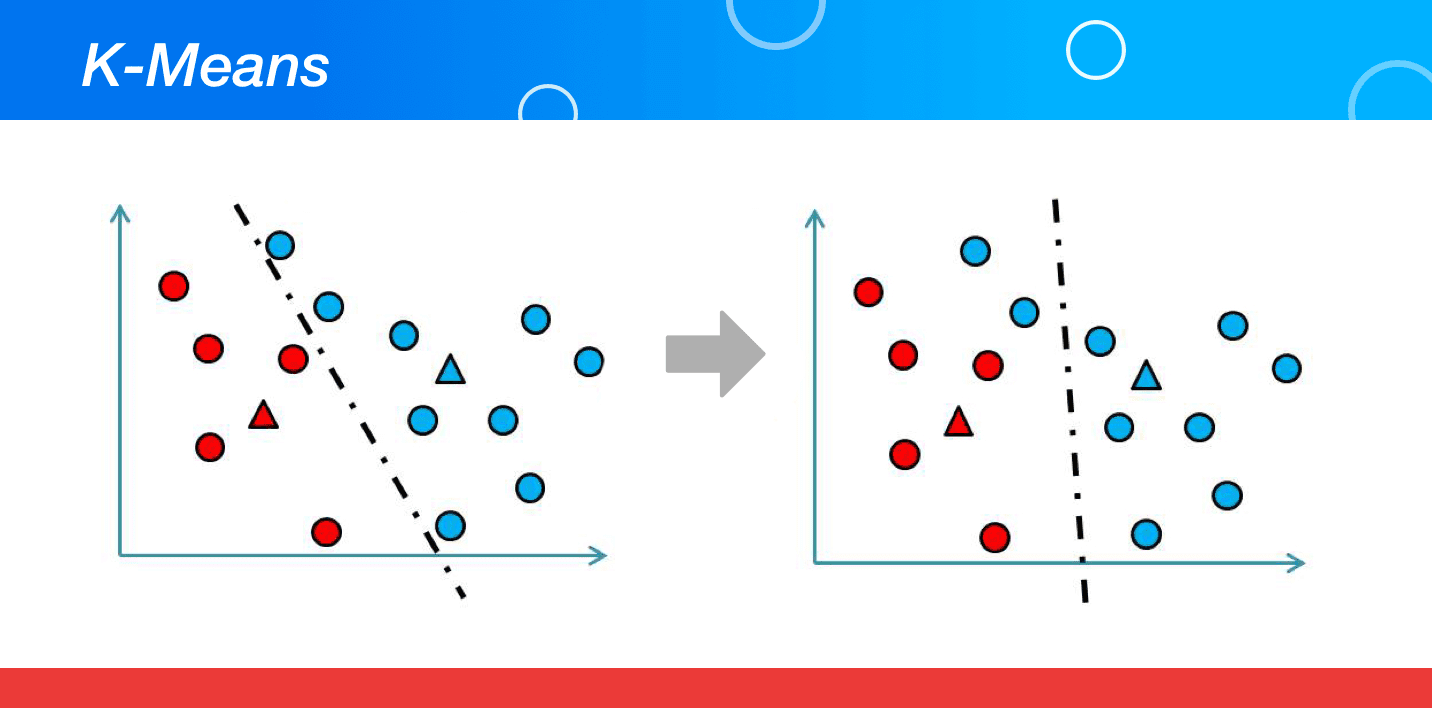 An unsupervised algorithmic program that is mainly used for solving clustering problems is titled K-Agency. The data sets in this algorithm are classified into a number of data sets following a particular identification number of clusters. This is carried out in a manner that all the information points falling within a cluster turn homogeneous or heterogeneous in comparison to the data that falls in other clusters.
An unsupervised algorithmic program that is mainly used for solving clustering problems is titled K-Agency. The data sets in this algorithm are classified into a number of data sets following a particular identification number of clusters. This is carried out in a manner that all the information points falling within a cluster turn homogeneous or heterogeneous in comparison to the data that falls in other clusters.
K-Agency form clusters by pick a "k" number of points named centroids for every cluster. All the data points create a cluster with the nearest centres of the K clusters. It then creates raw centroids dependent on the existing cluster members. With the help of new centres, the nearest outstrip for every data repoint gets discovered. This process keeps occurring till the time centroids reach a point of no change.
8. Random Forest
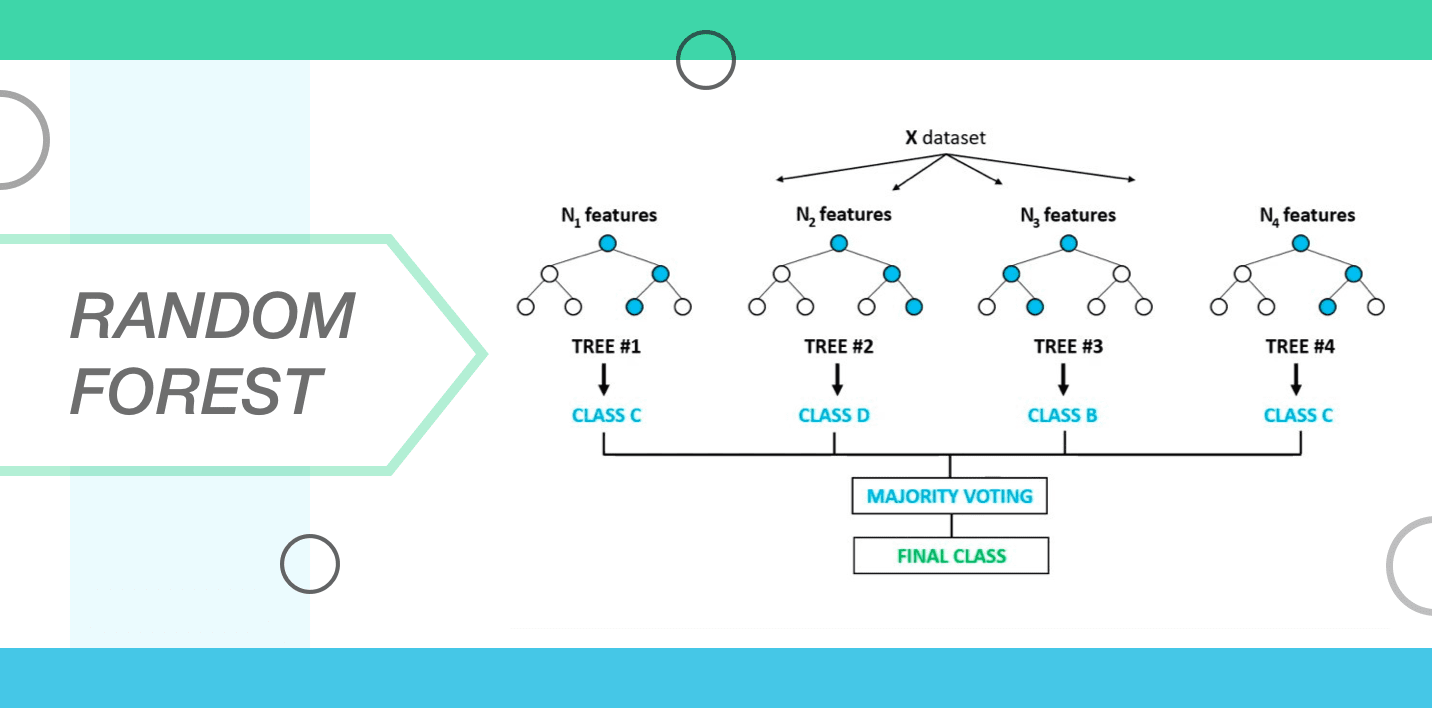 A group of decision trees is commonly referred to as a random forest. Systematic to classify a new object which is reliant on its attributes, all the trees are classified and they vote for the class. Following this, the forest chooses the classification that has the maximum number of votes as compared to all other trees in the woods. Complete the trees get soil-building and they grow as mentioned below.
A group of decision trees is commonly referred to as a random forest. Systematic to classify a new object which is reliant on its attributes, all the trees are classified and they vote for the class. Following this, the forest chooses the classification that has the maximum number of votes as compared to all other trees in the woods. Complete the trees get soil-building and they grow as mentioned below.
- The number of cases in the training set is appropriated as "N". A sample distribution of "N" cases is then taken at random and this sample is used atomic number 3 a training set for growing the tree.
- At the meter when the input signal variables are M so a number m<M gets labelled and so that at all node, the m variable gets selected at stochastic out of M variables and the best split on m can be used for splitting the mode. The m prise that gets derived is known as a constant passim the unharmed process.
- Every shoetree is grown to the extent that there is no pruning.
9. Dimensionality Reduction Algorithms
 In the present Earth, there is a huge amount of data that is stored and analyzed by organizations of all kinds. It is the responsibility of the data scientist to ensure that this raw information stays protected. Referable the fact that it contains huge information, the most important limitation is to key relevant patterns and variables.
In the present Earth, there is a huge amount of data that is stored and analyzed by organizations of all kinds. It is the responsibility of the data scientist to ensure that this raw information stays protected. Referable the fact that it contains huge information, the most important limitation is to key relevant patterns and variables.
The dimensionality reduction algorithms like Factor Analysis, Random Forest, Missing Treasure Ratio, Decision Sir Herbert Beerbohm Tree, etc. bathroom help in determination the important details.
10. Gradient Boosting and AdaBoost
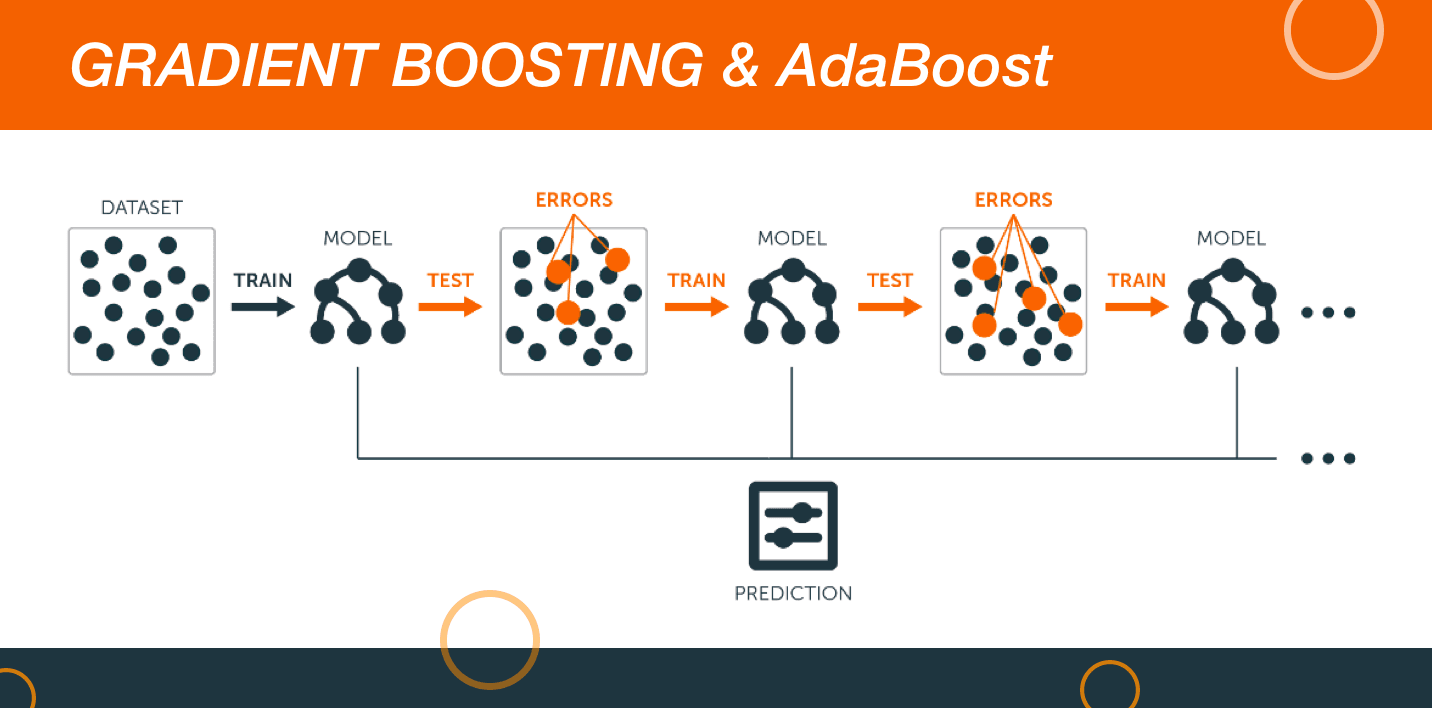 The two algorithms utilize a large total of data for managing predictions with precision. More surgery less, boosting is alike an ensemble encyclopedism algorithm that includes the predictive scholarship power of various base estimators for enhancing robustness.
The two algorithms utilize a large total of data for managing predictions with precision. More surgery less, boosting is alike an ensemble encyclopedism algorithm that includes the predictive scholarship power of various base estimators for enhancing robustness.
In swordlike terms, information technology brings together the weak predictors for the purpose of creating a rather strong predictor. The boosting algorithms have a reputation of working really well in the data science competitions. They are well-advised as highly preferred machine encyclopaedism algorithms. Information scientists in the main use of goods and services them with Python and R Codes for achieving accurate outcomes.
Conclusion
Preceding mentioned is the list of ten machine algorithms that all data scientists must know about. A very common determination successful past beginners in the field of information science is choosing the right data science algorithm to use. The correct choice for this ingredien depends entirely on some important highlights that admit the sized, the quality raze, information's nature, machine metre at handwriting, task priorities, and the aim for utilizing the data.
Consequently, regardless of the fact if you are newly or intimate in the field of data science, opt any incomparable of the algorithms mentioned above to amaze maximum results.
Which ML algorithms would you choose and for which scenarios? Let us know!
People are also reading:
- Top Auto Learning Certifications
- Best Machine Learning Books
- Unsurpassable Machine Learning Frameworks
- Types of Car Learning
- How to Become a Machine Learning Engineer?
- Top Machine Learning Interview Questions and Answers
- Difference between Supervised learning vs unsupervised learning
- Difference between AI vs Machine Learning
- Difference 'tween Machine Encyclopedism vs Deep learning
- Difference of opinion between Machine Learning vs Information Science
- ML Applications
DOWNLOAD HERE
Top 10 Machine Learning Algorithms for ML Beginners [Updated] Free Download
Posted by: strongplact1998.blogspot.com







0 Komentar
Post a Comment